Overview
Anonymous Authors
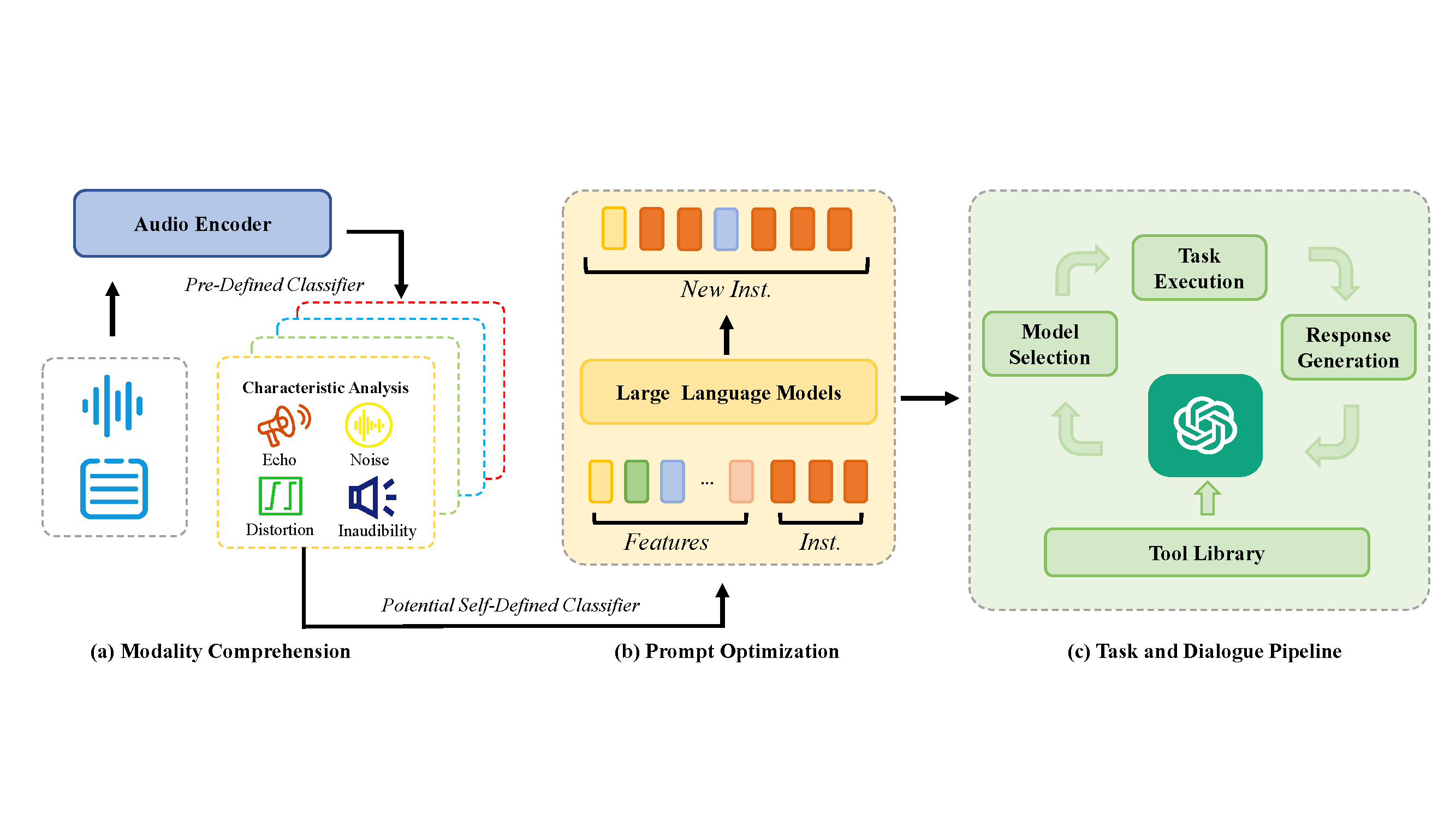
Abstract. While Large Language Models (LLMs) demonstrate significant potential as controllers in agent fields, effectively interpreting user instructions and selecting appropriate tools for audio tasks, they rely solely on textual input for selection. This reliance, however, overlooks valuable information inherent in the audio modality that could disambiguate user instructions and improve tool selection. To this end, we introduce AudioAgent, a versatile and adaptable agent framework for audio fields. It is the first system that emphasizes audio comprehension and utilizes this information to refine user-provided instructions by one finetuned LLM autonomously. Through clearer instructions, AudioAgent empowers the controller to make more precise selections from our comprehensive audio tool library, ultimately enhancing overall task performance. Our framework also allows users to freely register tools and utilize any LLM as the core controller. Both subjective and objective metrics validate the effectiveness of our work.
In this section, we provide some examples of our Prompt Optimization part. We list Raw Instruction, Ground Truth(GT), AudioAgent's result. Raw Instruction means inadequate instructions which serve as input in our dataset, GT means the the target output in the dataset. Ours means the result from modality comprehension and prompt optimizaion
| Audio Sample | Raw Instruction | GT | Ours |
|---|---|---|---|
In this section, we provide some examples to showcase the enhancement by AudioAgent's optimal selection of the suitable tool. Here is Speech Transcription. The Prompt is the raw input for these 2 Agent. Moreover, the tool in AudioGPT only support English when receving the raw input, so it behaves poorly in other language.
| Audio Sample | Prompt | Optimized_Prompt | Target Output | AudioGPT | Qwen2-Audio | AudioAgent |
|---|---|---|---|---|---|---|
In this section, we provide some examples to showcase the enhancement by AudioAgent's optimal selection of the suitable tool. Here is Speech Transcription. Moreover, the tool in AudioGPT can't finish the task without language type, so we only provide examples on Qwen2-Audio.
| Audio Sample | Content | Prompt | Optimized_Prompt | Target Output | Qwen2-Audio | AudioAgent |
|---|---|---|---|---|---|---|
In this section, we provide some examples to showcase the enhancement by AudioAgent's optimal selection of the suitable tool. Here is Audio Enhancement. Qwen2-Audio lacks the ability to finish such task.
| Audio Sample | Prompt | Optimized_Prompt | AudioGPT | AudioAgent |
|---|---|---|---|---|